Ě Š Č Ř Ž Ý Á Í É Ú Ů Ď Ť Ň Ó
Š Ť Ž Ľ Č Ď Ň Ĺ Ŕ Ý Á Í É Ú Ó Ô Ä
Ł Ą Ż Ę Ć Ń Ś Ź
Š Č Ž Ć Đ
прстуфхцчшщьыъэюя
АБВГДЕЁЖЗИЙКЛМНО
ПРСТУФХЦЧШЩЬЫЪЭЮЯ
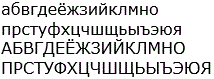
Source: SLOVO, adapted by Alkas
UNICODE is a really great 2-byte encoding that gives every letter of any writing system in the world a unique code number. Therefore, on one page you can write in various writing systems - this was impossible before UNICODE existed, because you had to switch to various codepages depending on language, like "Latin 1", "Latin 2" or "Cyrillic". Now you can have it all in one single web page!
Moreover, the coding system is designed so that the basic Latin characters (a, b, c,...) remain coded by 1 byte, and only the Latin letters with diacritical signs, and also letters ot another writing systems are 2-byte coded. This helps to reduce size of text files in the most of Latin based writing systems.
Our example shows Latin letters with diacritical marks of Central European languages and Cyrillic characters.
If you can see all letters in the middle column of the table as they
are in the right column your browser supports UNICODE UTF-8 encoding.
Your browser should automatically switch to UNICODE UTF-8 encoding because
this page contains "charset=utf-8" tag in header.
This page covers only some subsets of UNICODE UTF-8 used for Central and East European languages.
|
|
|
|
| Czech characters | ě š č ř ž ý á í é ú ů ď ť ň ó
Ě Š Č Ř Ž Ý Á Í É Ú Ů Ď Ť Ň Ó |
|
| Slovak characters | š ť ž ľ č ď ň ĺ ŕ ý á í é ú ó ô ä
Š Ť Ž Ľ Č Ď Ň Ĺ Ŕ Ý Á Í É Ú Ó Ô Ä |
|
| Polish characters | ł ą ż ę ć ń ś ź
Ł Ą Ż Ę Ć Ń Ś Ź |
|
| Romanian characters | Ă ă Ş ş Ţ ţ | |
| Croatian and Slovenian characters | š č ž ć đ
Š Č Ž Ć Đ |
|
| Hungarian characters | Ő ő Ű ű | |
| German characters | Ä, ä, Ö, ö, Ü, ü, ß | |
| Russian alphabet | абвгдеёжзийклмно
прстуфхцчшщьыъэюя АБВГДЕЁЖЗИЙКЛМНО ПРСТУФХЦЧШЩЬЫЪЭЮЯ |
|
| Special Byelorussian and Ukrainian characters | Ў ў Є є Ґ ґ | |
| Special Serbian and Macedonian characters | Ђ Љ Њ Ћ Џ ђ љ њ ћ џ |
Successfully tested on:
More information: UNICODE Web Site