Ě Š Č Ř Ž Ý Á Í É Ú Ů Ď Ť Ň Ó
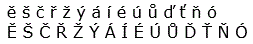
Š Ť Ž Ľ Č Ď Ň Ĺ Ŕ Ý Á Í É Ú Ó Ô Ä
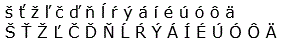
Ł Ą Ż Ę Ć Ń Ś Ź
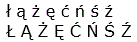
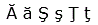
Š Č Ž Ć Đ
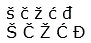
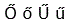
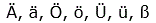
прстуфхцчшщьыъэюя
АБВГДЕЁЖЗИЙКЛМНО
ПРСТУФХЦЧШЩЬЫЪЭЮЯ
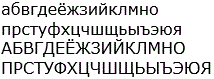
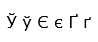
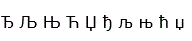
Zdroj: SLOVO, upravil Alkas
UNICODE UTF-8 je znamenité dvoubytové kódování, které přiřazuje každému písmenu každého písma světa jedinečné kódové číslo. Proto můžete na jednu stránku psát ve více písmech (více abecedách a více jazycích), což dříve bez UNICODE nebylo možné, protože byste museli přepínat různé kódové stránky podle použitého jazyka, například "Latin 1", "Latin 2" nebo "Cyrillic". Nyní je můžete mít všechny na jediné webové stránce!
Kódování je navíc navrženo tak, že dvěma byty se kódují pouze písmena latinky s diakritickými znaménky a písmena jiných písem (abeced), kdežto základní písmena latinky bez diakritických znamének (a, b, c,...) jsou stále kódována v jednom bytu. Tím se ve většině jazyků s písmem založeným na latince šetří místo.
Náš příklad ukazuje písmena latinky s diakritickými znaménky středoevropských jazyků a znaky cyrilice (azbuky) jiho- a východoevropských jazyků.
Shodují-li se všechna písmena prostředního a pravého sloupce tabulky (vpravo jsou obrázky), zvládá Váš prohlížeč kódování UNICODE UTF-8. Váš prohlížeč by se měl automaticky přepnout na kódování UNICODE UTF-8, protože tato stránka má příznak "charset=utf-8" v záhlaví (v sekci <head>).
Tato stránka obsahuje pouze určitou podmnožinu znaků UNICODE UTF-8, používanou ve středo-, jiho- a východoevropských jazycích.
|
|
|
|
| Česká písmena | ě š č ř ž ý á í é ú ů ď ť ň ó
Ě Š Č Ř Ž Ý Á Í É Ú Ů Ď Ť Ň Ó |
|
| Slovenská písmena | š ť ž ľ č ď ň ĺ ŕ ý á í é ú ó ô ä
Š Ť Ž Ľ Č Ď Ň Ĺ Ŕ Ý Á Í É Ú Ó Ô Ä |
|
| Polská písmena | ł ą ż ę ć ń ś ź
Ł Ą Ż Ę Ć Ń Ś Ź |
|
| Rumunská písmena | Ă ă Ş ş Ţ ţ | |
| Chorvatská a slovinská písmena | š č ž ć đ
Š Č Ž Ć Đ |
|
| Maďarská písmena | Ő ő Ű ű | |
| Německá písmena | Ä, ä, Ö, ö, Ü, ü, ß | |
| Ruská azbuka (Cyrilice) | абвгдеёжзийклмно
прстуфхцчшщьыъэюя АБВГДЕЁЖЗИЙКЛМНО ПРСТУФХЦЧШЩЬЫЪЭЮЯ |
|
| Zvláštní běloruská a ukrajinská písmena | Ў ў Є є Ґ ґ | |
| Zvláštní srbská a makedonská písmena | Ђ Љ Њ Ћ Џ ђ љ њ ћ џ | |
V českém jazyce a písmu se diakritická znaménka demonstrují touto větou:
úplně žluťoučký kůň šířil ďábelské ódy / ÚPLNĚ ŽLUŤOUČKÝ KŮŇ ŠÍŘIL ĎÁBELSKÉ ÓDY
Její hexadecimální tvar (v malé abecedě) je:
C3BA 70 6C 6E C49B 20 C5BE 6C 75 C5A5 6F 75 C48D 6B C3BD 20 6B C5AF C588 20 C5A1 C3AD C599 69 6C 20 ...
ú p l n ě ž l u ť o u č k ý k ů ň š í ř i l ...
Zde je vidět, jak písmena latinky bez diakritických znamének zůstávají zakódována každé v jednom byte,
kdežto písmena s diakritickými znaménky jsou kódována každé dvěma byty; ta použitá zde začínají "C".
Úspěšně testováno na:
Další informace: web UNICODE